> ## Documentation Index
> Fetch the complete documentation index at: https://docs.hipocap.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Laminar Manual Evaluation
The Laminar Manual Evaluation SDK and API provide you with **granular control** over the evaluation process, allowing you to integrate Laminar directly into your existing evaluation pipeline or create flexible and complex evaluation workflows.
## Manual vs. SDK Evaluation
Use manual evaluation when you need granular control over the evaluation lifecycle, custom tracing, or want to integrate evaluations with complex workflows.
The manual evaluation approach gives you fine-grained control over:
* **Step-by-step execution** tracking
* **Flexible evaluation logic** and scoring
* **Integration** with existing systems and workflows
## How Manual Evaluation Works
Manual evaluation follows a structured workflow with three core components:
1. **Create Evaluation** - Initialize a new evaluation
2. **Execute and Evaluate** - Run your logic and evaluate it
* Run your core logic
* Run your evaluation logic
3. **Save and Update** - Store datapoints and evaluation results
## Quickstart
Let's walk through implementing manual evaluation with tracing, breaking down each component:
### Step 1: Setup and Initialization
First, initialize Laminar and create your evaluation clients:
```javascript JavaScript theme={null}
import { Laminar, LaminarClient, observe } from "@lmnr-ai/lmnr";
import { OpenAI } from "openai";
Laminar.initialize({
projectApiKey: 'your_project_api_key',
instrumentModules: {
openAI: OpenAI // Automatically traces OpenAI calls
}
});
const client = new LaminarClient({
projectApiKey: 'your_project_api_key',
});
const openai = new OpenAI({ apiKey: 'your_openai_api_key' });
```
```python Python theme={null}
import asyncio
from lmnr import Laminar, LaminarClient, observe
from openai import AsyncOpenAI
Laminar.initialize(project_api_key='your_project_api_key')
client = LaminarClient(project_api_key='your_project_api_key')
openai_client = AsyncOpenAI(api_key='your_openai_api_key')
```
### Step 2: Create Your Executor and Evaluation logic
* Our executor function makes a call to OpenAI and is wrapped with tracing:
```javascript JavaScript theme={null}
const executeTestCase = async (testCase) => {
return await observe(
{ name: 'executor', spanType: 'EXECUTOR', input: testCase.data },
async () => {
const response = await openai.chat.completions.create({
model: 'gpt-4o-mini',
messages: [
{
role: 'user',
content: `What is the capital of ${testCase.data.country}? ` +
'Answer only with the capital, no other text.'
}
]
});
return response.choices[0].message.content || '';
}
);
};
```
```python Python theme={null}
@observe(name='executor', span_type='EXECUTOR')
async def execute_test_case(test_case):
response = await openai_client.chat.completions.create(
model='gpt-4o-mini',
messages=[
{
'role': 'user',
'content': f"What is the capital of {test_case['data']['country']}? " +
'Answer only with the capital, no other text.'
}
]
)
return response.choices[0].message.content or ''
```
* Then our evaluator function `accuracy` is going to measure accuracy of executor.
```javascript JavaScript theme={null}
const accuracy = async (output, target) => {
return await observe(
{ name: 'accuracy', spanType: 'EVALUATOR', input: { output, target } },
async () => {
if (!target) return 0;
return output.includes(target) ? 1 : 0;
}
);
};
```
```python Python theme={null}
@observe(name='accuracy', span_type='EVALUATOR')
async def accuracy(output, target):
if not target:
return 0
return 1 if target in output else 0
```
### Step 3: Create Evaluation and Datapoints
First, you need to create an evaluation session, then create datapoints with test data and update them with execution results and scores.
**Create Evaluation**
Before creating datapoints, you must initialize an evaluation session:
```javascript JavaScript theme={null}
const evalId = await client.evals.create({
name: "Capital of Country Manual Eval",
groupName: "Manual API - Capital Cities"
});
```
```python Python theme={null}
eval_id = client.evals.create_evaluation(
name="Capital of Country Manual Eval",
group_name="Manual API - Capital Cities"
)
```
**Create/Update Datapoints**
The most important aspect is connecting your evaluation datapoints to the current execution trace using `trace_id` / `traceId`.
This makes it possible to attach the created spans to a trace, which can then be inspected later in trace view.
You need to call `Laminar.getTraceId()` / `Laminar.get_trace_id()` inside of context of span to get id of trace.
We strongly advise to call `createDatapoint` / `create_datapoint` before calling executor/evaluator so trace can be associated as evaluation trace type.
```javascript JavaScript highlight={7} theme={null}
const datapointId = await client.evals.createDatapoint({
evalId,
data: testCase.data,
target: testCase.target,
index: i,
// Must be called within span context
traceId: Laminar.getTraceId(),
});
await client.evals.updateDatapoint({
evalId,
datapointId,
scores: { accuracy: accuracyScore },
executorOutput: {
response: output,
model: 'gpt-4o-mini',
country: testCase.data.country
},
});
```
```python Python highlight={7} theme={null}
datapoint_id = client.evals.create_datapoint(
eval_id=eval_id,
data=test_case['data'],
target=test_case['target'],
index=i,
# Must be called within span context
trace_id=Laminar.get_trace_id(),
)
client.evals.update_datapoint(
eval_id=eval_id,
datapoint_id=datapoint_id,
scores={'accuracy': accuracy_score},
executor_output={
'response': output,
'model': 'gpt-4o-mini',
'country': test_case['data']['country']
},
)
```
## Complete Example
```javascript JavaScript [expandable] theme={null}
import { Laminar, LaminarClient, observe } from "@lmnr-ai/lmnr";
import { OpenAI } from "openai";
Laminar.initialize({
projectApiKey: 'your_project_api_key',
instrumentModules: {
openAI: OpenAI
}
});
const client = new LaminarClient({
projectApiKey: 'your_project_api_key',
});
const openai = new OpenAI({ apiKey: 'your_openai_api_key' });
const executeTestCase = async (testCase) => {
return await observe(
{ name: 'executor', spanType: 'EXECUTOR', input: testCase.data },
async () => {
const response = await openai.chat.completions.create({
model: 'gpt-4o-mini',
messages: [
{
role: 'user',
content: `What is the capital of ${testCase.data.country}? ` +
'Answer only with the capital, no other text.'
}
]
});
return response.choices[0].message.content || '';
}
);
};
const accuracy = async (output, target) => {
return await observe(
{ name: 'accuracy', spanType: 'EVALUATOR', input: { output, target } },
async () => {
if (!target) return 0;
return output.includes(target) ? 1 : 0;
}
);
};
async function runEvaluation() {
try {
const testData = [
{
data: { country: 'France' },
target: 'Paris',
},
{
data: { country: 'Germany' },
target: 'Berlin',
},
];
const evalId = await client.evals.create({
name: "Capital of Country Manual Eval",
groupName: "Manual API - Capital Cities"
});
for (let i = 0; i < testData.length; i++) {
await observe(
{ name: 'evaluation', spanType: 'EVALUATION', input: { testCase: testData[i] } },
async () => {
const testCase = testData[i];
// Save datapoint first to associate trace as evaluation type
const datapointId = await client.evals.createDatapoint({
evalId,
data: testCase.data,
target: testCase.target,
index: i,
// Must be called within span context
traceId: Laminar.getTraceId(),
});
const output = await executeTestCase(testCase);
const accuracyScore = await accuracy(output, testCase.target)
await client.evals.updateDatapoint({
evalId,
datapointId,
scores: { accuracy: accuracyScore },
executorOutput: {
response: output,
model: 'gpt-4o-mini',
country: testCase.data.country
},
});
}
);
}
await Laminar.flush();
} catch (error) {
console.error("Error:", error.message);
}
}
runEvaluation();
```
```python Python [expandable] theme={null}
import asyncio
from lmnr import Laminar, LaminarClient, observe
from openai import AsyncOpenAI
Laminar.initialize(project_api_key='your_project_api_key')
client = LaminarClient(project_api_key='your_project_api_key')
openai_client = AsyncOpenAI(api_key='your_openai_api_key')
@observe(name='executor', span_type='EXECUTOR')
async def execute_test_case(test_case):
response = await openai_client.chat.completions.create(
model='gpt-4o-mini',
messages=[
{
'role': 'user',
'content': f"What is the capital of {test_case['data']['country']}? " +
'Answer only with the capital, no other text.'
}
]
)
return response.choices[0].message.content or ''
@observe(name='accuracy', span_type='EVALUATOR')
async def accuracy(output, target):
if not target:
return 0
return 1 if target in output else 0
@observe(name='evaluation', span_type='EVALUATION')
async def run_evaluation_session(eval_id, i, test_case):
# Save datapoint first to associate trace as evaluation type
datapoint_id = client.evals.create_datapoint(
eval_id=eval_id,
data=test_case['data'],
target=test_case['target'],
index=i,
# Must be called within span context
trace_id=Laminar.get_trace_id(),
)
output = await execute_test_case(test_case)
accuracy_score = await accuracy(output, test_case['target'])
client.evals.update_datapoint(
eval_id=eval_id,
datapoint_id=datapoint_id,
scores={'accuracy': accuracy_score},
executor_output={
'response': output,
'model': 'gpt-4o-mini',
'country': test_case['data']['country']
},
)
async def run_evaluation():
try:
test_data = [
{
'data': {'country': 'France'},
'target': 'Paris',
},
{
'data': {'country': 'Germany'},
'target': 'Berlin',
},
]
eval_id = client.evals.create_evaluation(
name="Capital of Country Manual Eval",
group_name="Manual API - Capital Cities"
)
for i, test_case in enumerate(test_data):
await run_evaluation_session(eval_id, i, test_case)
Laminar.flush()
except Exception as error:
print(f"Error: {error}")
if __name__ == "__main__":
asyncio.run(run_evaluation())
```
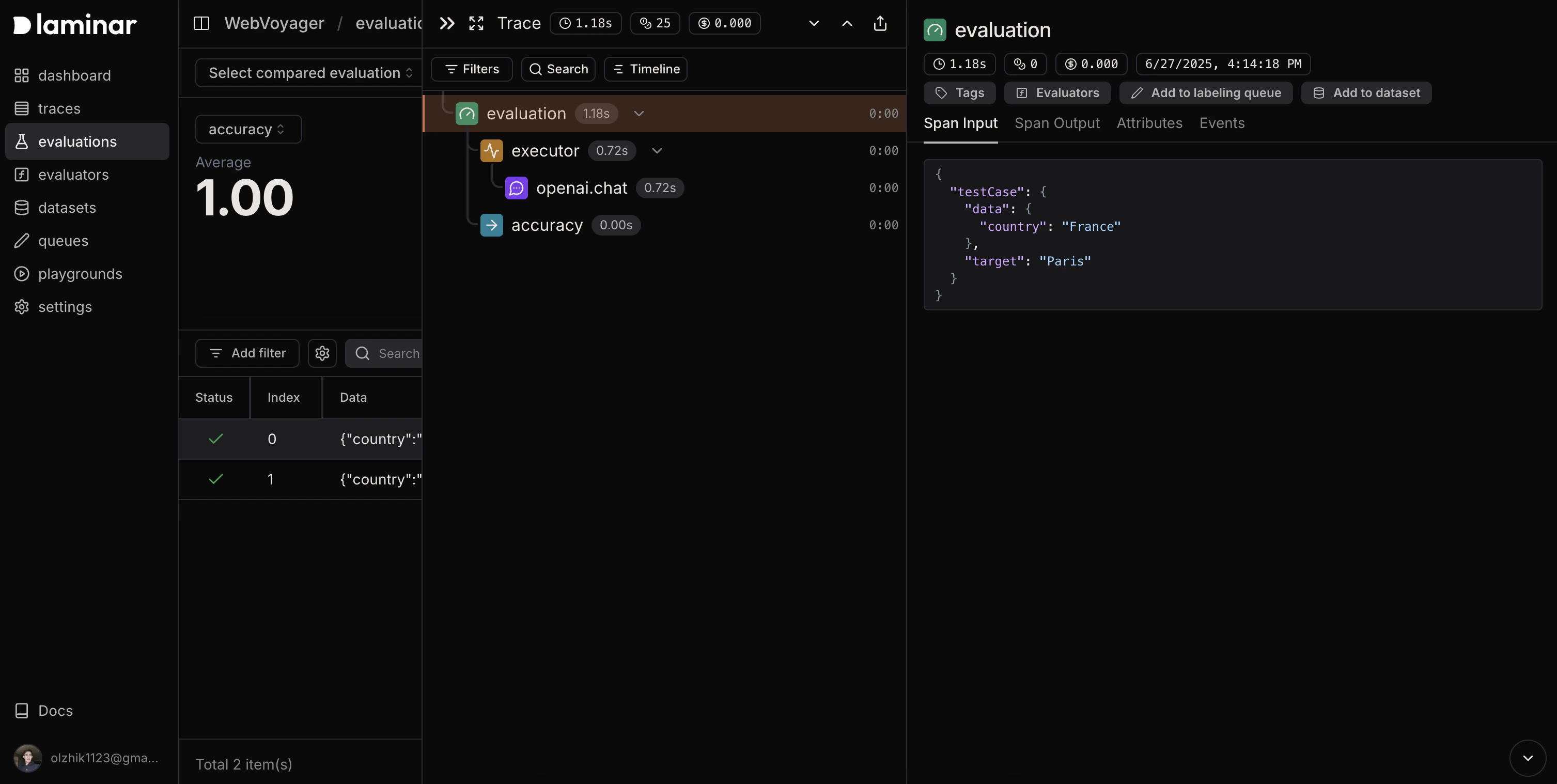
## Evaluation Results
When you run the following example of manual evaluation, you'll see detailed tracing and evaluation results in your Laminar dashboard: